
Most keyword research tools have some limits before they stop outputting reliable results. For example, Google Keyword Planner will stop after around 100 searches of 10 keywords each. If you acquired a very a large number of keywords, (for example autosuggest, or entities from multiple articles), you will want to typically use some filter on them so you don’t waste your keyword tool’s resources.
The idea is to find a resource that is decently representative of the whole internet and can be easily processed.
Wikipedia and its article dumps are as good as they get for our needs.
- Go to Wikipedia dump page and select the newest wikidatawiki.
- Download the newest wikidatawikifile, or 100 file versions of it. Either one will take a while to download.
- Decompress the file or files, and you will get a bunch of XML files that can be parsed.
- In your favourite DB create a table with keyword and counter columns, with keyword as the primary key
- With your favourite programming language, open the XML file and parse individual words in the article content
- Add each parsed word in the table, increasing the counter every time it is added. You can just use something like “INSERT ignore INTO wiki_counter VALUES (‘$keyword’) ON DUPLICATE KEY UPDATE counter = counter+1”
- This will give us a table with all the words in wikipedia in one column and their frequency in the other column. In phpMyAdmin it would look like this:
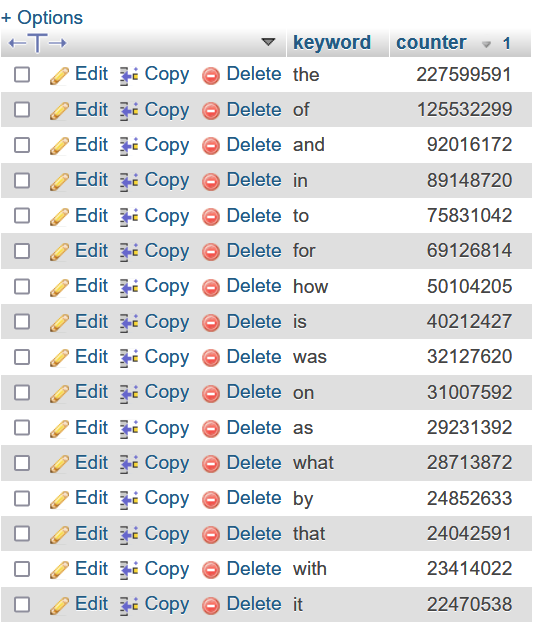
- Someone already did this last year at a https://github.com/IlyaSemenov/wikipedia-word-frequency/blob/master/results/enwiki-2022-08-29.txt but if you want more up-to-date data you will have to parse it yourself.
- Now that we have this info we can parse a file with millions of keywords and for every keyword we can assign a score.
- There are many ways we can go about assigning keywords a score. For every word in a keyword, I would look up the counter value in the DB, take the square root of the counter value and assign it to the word. The reason I use square root of the counter is that common words have a counter that is too high and would skew the results. Using the square root gives better results overall.
- Optional: ignore common “stop” words and numbers.
- For every keyword, add up all the individual word scores, and divide by the number of words. This will give the average score of the whole word.
- This will give us a list of keywords and their score that represents how often the words in the keyword appear in Wikipedia (and likely the internet as a whole.
- This is an example of some SEO related words that are scored, with the highest score being the most competitive and lowest score being the least competitive:
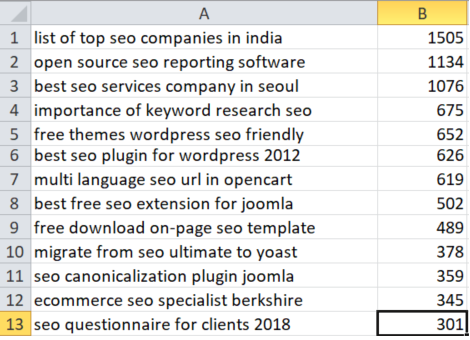
This method can sort millions of keywords in minutes, saving you a lot of time and resources.
Important Disclaimer: This method is fantastic for prioritizing low competition keywords, but can falsely identify some keywords as high competition. As an example, if a keyword contains words that are common, but don’t often appear together (let’s say “fastest chicken motherboard”) it will assign this word a high competition score even though barely any pages on the web contain all those words TOGETHER. But this algorithm works really well when looking to prioritize words with a low frequency for further SEO research.